
Projects
Fate of carbon in soils: Using self-supervised language models on sequence data from subsurface microbial communities
PI: Woodward W. Fischer (Division of Geological and Planetary Science)
SASE: Pippa Richter, Scholar
Approximately one-third of the CO2 emitted from fossil fuel burning and land use change has been drawn out of the atmosphere and fixed into organic matter by the biosphere. As CO2 increases in the atmosphere and the climate warms, the biosphere is becoming more productive. This increase in primary productivity has outpaced that of respiration; the net process is locking CO2 away into organic matter—somewhere, somehow. Moreover this enhanced CO2 removal by the biosphere has been taking place for more than a hundred years. That carbon is not simply found in trees or algae, but it is present in large part as particles transported across the globe that are bleeding into sedimentary deposits (soils, river floodplains, deltas and coastal sediments) with significant potential for permanent storage over societal timescales. And it's the convolution of physical, chemical, and ecological processes in the biosphere with processes that produce, transport, and bury soil and sediment that is controlling the cadence of this sequestration. Put another way, when carbon is fixed by the biosphere and enters soil and sedimentary reservoirs, can we have quantitative knowledge of if and when we will see it in the atmosphere again?
Subsurface microbial communities are the key catalysts controlling carbon transformations, and the taxonomic and genomic composition of communities provides a valuable time-integrated measure of the environmental conditions present in soils and sediments. Recent breakthroughs make it possible to access the genomic content of soil and sediment microbes in a high throughput fashion that is both rapid and inexpensive. The challenge is that the volume of data we recover is massive and complex. However, a promising approach to learning about soil and sediment conditions is via the metabolic states of the microbes that live there; information about soil O2 content, for example, could be gleaned by the relative quantities of aerobic and anaerobic bacteria in a sample. Put simply, can we figure out from sequence data who is an aerobe and who isn’t?
Protein language models have highlighted a particularly promising approach for deducing physical and chemical conditions in the subsurface via microbial metabolic states captured within large genomic datasets that are routinely generated from global field sites. The Scholar worked on the development of software usable by geobiologists and environmental scientists for accurately determining key characteristics of microbial metabolism using protein language models. This approach takes significant advantage of the tens of millions of dollars spent training language models to represent proteins by the AI research teams.
Aerobes require dioxygen (O2) to grow; anaerobes do not. However, nearly all microbes aerobes, anaerobes, and facultative organisms alike—express enzymes whose substrates include O2, if only for detoxification. This presents a challenge when trying to assess which organisms are aerobic from genomic data alone. This challenge can be overcome by noting that O2 utilization has wide-ranging effects on microbes: aerobes typically have larger genomes encoding distinctive O2-utilizing enzymes, for example. These effects permit high-quality prediction of O2 utilization from annotated genome sequences, with several models displaying ≈80% accuracy on a ternary classification task for which blind guessing is only 33% accurate.
However, genome annotation is compute-intensive and far simpler approaches based entirely on genomic sequence content—e.g., triplets of amino acids—perform as well as intensive annotation-based classifiers. Furthermore, amino acid trimers are useful because they encode information about protein composition and phylogeny. This motivated the Scholar to develop a machine-learning based tool – Aerobot – capable of predicting oxygen utilization in diverse environmental microbes. Statistical methods such as utilized by this tool might be used to estimate, or “sense,” pivotal features of the chemical environment using DNA sequencing data.
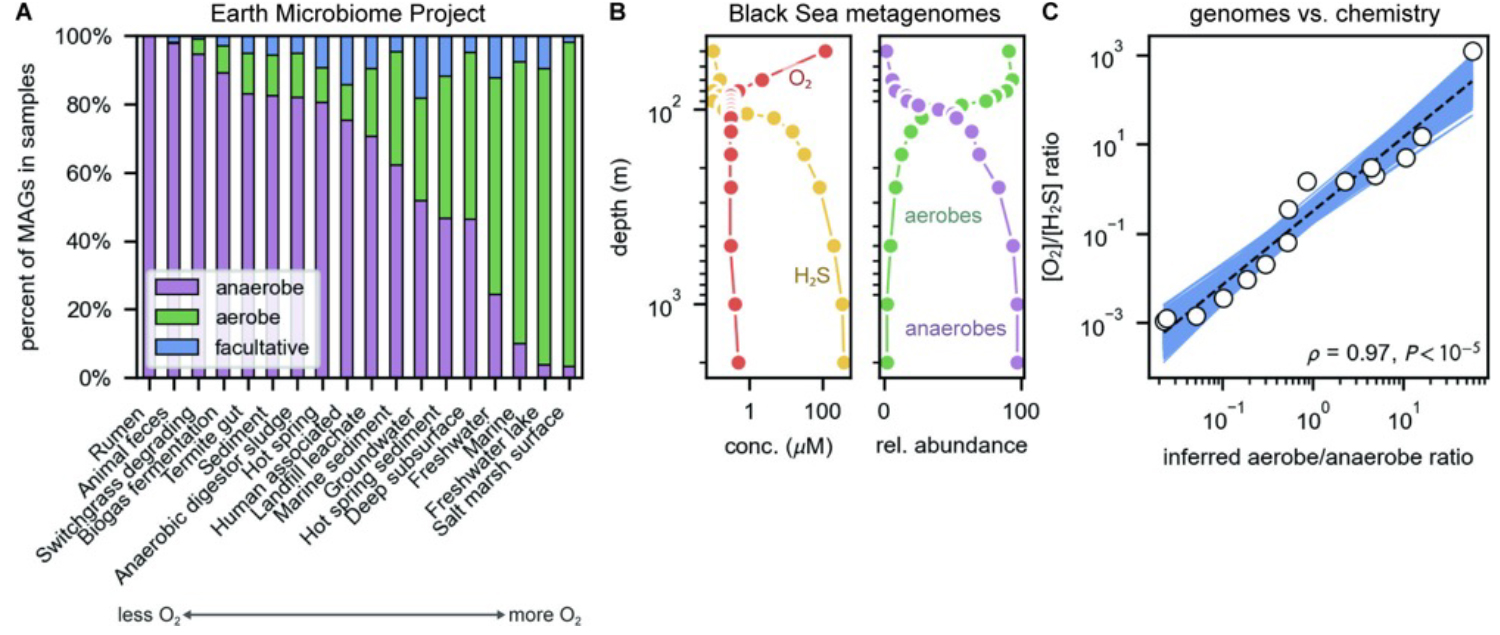
(A) We applied AeroBot to genomes associated with Earth Microbiome Project samples. Samples from environments with characteristically low O2 levels (e.g., rumen and anaerobic digesters) displayed greater anaerobe content, while oxic surface environments predominantly hosted aerobes (e.g., freshwater lakes). (B and C) The Black Sea is a well-studied stratified euxinic ecosystem with a long-lived systematic O2 gradient—oxygenated at the surface with a loss of O2 and an increase in sulfide with depth. (B) We applied the tool to 160 MAGs to estimate the depth-dependent prevalence of aerobes and anaerobes. Consistent with O2 and H2S profiles, aerobes were most prevalent near the surface and anaerobes most prevalent at depth. (C) The [O2]/[H2S] ratio was strongly correlated with the inferred aerobe/anaerobe ratio on a log–log plot such that estimating the oxygen gradient from sequencing data resulted in <80% relative error over roughly six orders.